# Patroni
[TOC]
# 环境
软件版本:
- Patroni:
3.0.2 - Python:
3.9.16 - DCS: Zookeeper
3.4.13 - Postgresql:
15.3
节点信息:
| 节点名称 | IP地址 | 端口 | 角色(初始时) | DC(datacenter) |
|---|---|---|---|---|
| node_172.16.245.4 | 172.16.245.4 | 5432 | Primary | 2 |
| node_172.16.245.5 | 172.16.245.5 | 5432 | Sync Standby | 2 |
| node_172.16.245.6 | 172.16.245.6 | 5432 | Primary | 3 |
# watchdog
# 1. 使用
安装软件狗 watchdog
# 安装
yum install watchdog -y;
# 加载软件狗
modprobe softdog;
# 设置开启自启
systemctl enable watchdog;
# 2. 问题
# 1. [Errno 2] No such file or directory: '/dev/watchdog'
Patroni 报错
2023-07-30 16:36:02,915 WARNING: Could not activate Linux watchdog device: Can't open watchdog device: [Errno 2] No such file or directory: '/dev/watchdog'解决方法:安装软件狗或者硬件狗
# 2. [Errno 13] Permission denied: '/dev/watchdog'"
patroni 报错
2023-07-30 14:30:10,087 WARNING: Could not activate Linux watchdog device: "Can't open watchdog device: [Errno 13] Permission denied: '/dev/watchdog'"解决方法:修改权限
# 查看 ls -l /dev/watchdog crw------- 1 root root 10, 130 Feb 18 13:52 /dev/watchdog # 修改权限 chmod 666 /dev/watchdog # 查看 ls -l /dev/watchdog crw-rw-rw- 1 root root 10, 130 Feb 18 13:52 /dev/watchdog
# PostgreSQL
# 1. 同步复制槽的流程
根据传入的dcs_failed参数和集群状态,它决定是否需要操作复制槽。如果dcs_failed为True,表示与DCS的通信失败,此时如果当前节点是领导者或故障安全模式未启用,则不会处理复制槽。否则,根据集群的状态和配置来决定是否需要进行复制槽的同步操作。如果故障安全模式处于活动状态,则不进行复制槽的同步。最终,返回一个需要从主库复制的复制槽名称的列表。
读取复制槽的流程
Patroni 首先会根据不同的 PG 主版本生成一些 SQL,有以下一些内容:
if self._postgresql.major_version >= 90400 and self._schedule_load_slots: replication_slots: Dict[str, Dict[str, Any]] = {} extra = ", catalog_xmin, pg_catalog.pg_wal_lsn_diff(confirmed_flush_lsn, '0/0')::bigint" \ if self._postgresql.major_version >= 100000 else "" skip_temp_slots = ' WHERE NOT temporary' if self._postgresql.major_version >= 100000 else ''pg_catalog.pg_wal_lsn_diff()这个函数用于计算两个 WAL LSN(Write-Ahead Log Logical Sequence Number)之间的差值。这个函数接受两个参数,都是 WAL LSN 的文本表示形式。它会计算第二个参数与第一个参数之间的差值,并返回一个bigint类型的结果,表示这两个 WAL LSN 之间的日志段数差距。接下来会查询复制槽,如果 PG 主版本匹配,则会附带上面展示的 SQL 进行查询:
for r in self._query('SELECT slot_name, slot_type, plugin, database, datoid' f'{extra} FROM pg_catalog.pg_replication_slots{skip_temp_slots}'): value = {'type': r[1]} if r[1] == 'logical': value.update(plugin=r[2], database=r[3], datoid=r[4]) if self._postgresql.major_version >= 100000: value.update(catalog_xmin=r[5], confirmed_flush_lsn=r[6]) replication_slots[r[0]] = value
# Config
# 1. 使用 PyYAML 库对 .yaml 的配置文件进行修改会导致配置项顺序混乱以及注释被清除
在适配的过程中,检查配置项时,自动添加缺失的配置项时发现的这个问题,通过重写 PyYAML 库中的 load 和 dump 方法解决了修改数据导致的配置项顺序混乱的问题,但是似乎无法解决注释丢失的问题。通过网上的资料发现 ruamel.yaml 库可以更好的去处理 yaml 格式的配置文件,并且解决上述的问题,但是仅仅为了处理这个问题去替换 patroni 源码中的库或者添加一个新的库不太好,暂不使用这个方式。
重写的 load 和 dump 方法如下:
# write or read file in the original order
def ordered_yaml_load(stream, Loader=yaml.SafeLoader, object_pairs_hook=OrderedDict):
class OrderedLoader(Loader):
pass
def _construct_mapping(loader, node):
loader.flatten_mapping(node)
return object_pairs_hook(loader.construct_pairs(node))
OrderedLoader.add_constructor(
yaml.resolver.BaseResolver.DEFAULT_MAPPING_TAG,
_construct_mapping)
return yaml.load(stream, OrderedLoader)
def ordered_yaml_dump(data, stream=None, Dumper=yaml.SafeDumper, object_pairs_hook=OrderedDict, **kwds):
class OrderedDumper(Dumper):
pass
def _dict_representer(dumper, data):
return dumper.represent_mapping(
yaml.resolver.BaseResolver.DEFAULT_MAPPING_TAG,
data.items())
OrderedDumper.add_representer(object_pairs_hook, _dict_representer)
return yaml.dump(data, stream, OrderedDumper, **kwds)
注意:未解决配置文件注释丢失的问题。
# DCS
# 1. Patroni 在 DCS 中写入了什么?
在集群初始化后,DCS 中会在 /service/scope (根据 Patroni 中配置的 namespace 和 scope 组合成的路径)路径下创建以下几个节点:
注意:
- 在启用 citus 或 mmr 的情况下,
/service/scope路径会多一层group路径。- 本文档中测试环境使用的 DCS 技术是 Zookeeper,其中存储的数据格式为 JSON,不同的 DCS 技术可能存储的数据格式会不一样,但是存储的内容是一致的。
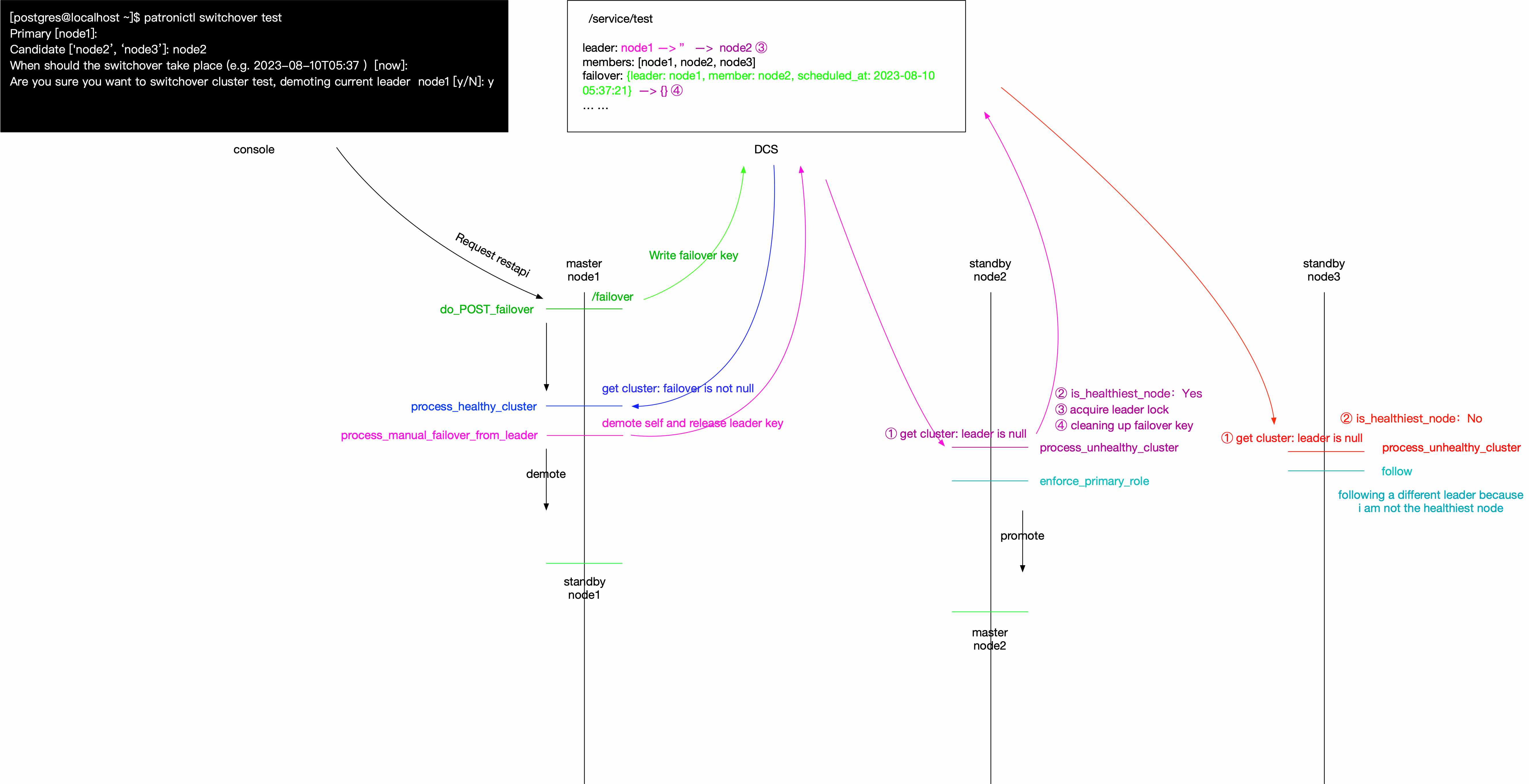
leader: 用于标识当前的领导者节点。这个键的值是领导者节点的名称。在领导者选举过程中,各个候选节点会竞争写入这个键,最终写入成功的节点将成为领导者。[zk: localhost:2181(CONNECTED) 7] get /service/test/2/leader node_172_16_245_4failover: 记录了故障切换的相关信息,如切换的目标节点、切换开始时间等。在进行手动或自动故障切换时,会写入这个键。members: 记录了集群中各个成员节点的状态、角色、连接信息等。包括节点名称、连接URL、角色(主库、从库)、状态等信息。# members 中包含着集群中的节点信息 [zk: localhost:2181(CONNECTED) 2] ls /service/test/2/members [node_172_16_245_4, node_172_16_245_5] [zk: localhost:2181(CONNECTED) 2] get /service/test/2/members/node_172_16_245_4 {"conn_url":"postgres://172.16.245.4:5432/postgres","api_url":"http://172.16.245.4:8008/patroni","state":"running","role":"master","version":"3.0.2","pending_restart":true,"xlog_location":50455880,"timeline":3}initialize: 记录集群初始化的状态。其中存储着数据库的sysid信息。这个信息对应pg_controldata命令中输出的Database system identifier。[zk: localhost:2181(CONNECTED) 0] get /service/test/2/initialize 7265080646965906116history: 记录了过去发生的故障切换操作的相关信息,如切换的时间、目标节点、切换类型等。[zk: localhost:2181(CONNECTED) 4] get /service/test/2/history [[1,50332376,"no recovery target specified","2023-08-03T20:35:14.405331-04:00","node_172_16_245_5"],[2,50400256,"no recovery target specified","2023-08-08T19:42:14.979349-04:00","node_172_16_245_4"]]config: 记录了 PostgreSQL 数据库的配置参数,用于在集群中的各个节点之间共享配置信息。[zk: localhost:2181(CONNECTED) 9] get /service/test/2/config {"ttl":30,"loop_wait":10,"retry_timeout":10,"maximum_lag_on_failover":1048576,"postgresql":{"use_pg_rewind":true,"parameters":{"listen_addresses":"*","port":5432,"max_connections":100,"shared_buffers":"128MB","logical_decoding_work_mem":"64MB","dynamic_shared_memory_type":"posix","wal_level":"logical","max_wal_size":"1GB","min_wal_size":"80MB","max_wal_senders":10,"max_replication_slots":10,"track_commit_timestamp":"on","max_sync_workers_per_subscription":4,"logging_collector":"on","log_directory":"log","log_filename":"postgresql-%a.log","log_rotation_age":"1d","log_rotation_size":0,"log_truncate_on_rotation":true,"log_min_messages":"debug1","log_min_error_statement":"debug1","log_timezone":"Asia/Shanghai","datestyle":"iso, mdy","timezone":"Asia/Shanghai","lc_messages":"C","lc_monetary":"C","lc_numeric":"C","lc_time":"C","default_text_search_config":"pg_catalog.english","shared_preload_libraries":"fdd_mmr","fdd.running_databases":"postgres, test_mmr, test_for_mmr","fdd.search_dead_tup_time_interval":5000}},"synchronous_mode":true}sync: 记录了同步模式下的相关信息,如同步节点列表、同步状态等。在同步模式下,各个节点会定期写入和更新这个键。[zk: localhost:2181(CONNECTED) 4] get /service/test/2/sync {"leader":"node_172_16_245_4","sync_standby":"node_172_16_245_5"}status: 记录了当前 leader 节点的 last_lsn(Optime)。用于在切换过程中确保数据一致性。[zk: localhost:2181(CONNECTED) 6] get /service/test/2/status {"optime":50456216}
# 2. dcs_modules [method]
在 dcs 的 __init__.py 中获取已经实现的 dcs 接口类方法中存在这么一个判断:
if getattr(sys, 'frozen', False):
toc: Set[str] = set()
# dcs_dirname may contain a dot, which causes pkgutil.iter_importers()
# to misinterpret the path as a package name. This can be avoided
# altogether by not passing a path at all, because PyInstaller's
# FrozenImporter is a singleton and registered as top-level finder.
for importer in pkgutil.iter_importers():
if hasattr(importer, 'toc'):
toc |= getattr(importer, 'toc')
return [module for module in toc if module.startswith(module_prefix) and module.count('.') == 2]
else:
return [module_prefix + name for _, name, is_pkg in pkgutil.iter_modules([dcs_dirname]) if not is_pkg]
参考 Pyinstaller 手册中描述:
您的应用程序应该在捆绑包中与从源代码运行时的表现完全一致。然而,您可能希望在运行时了解应用程序是从源代码运行还是已捆绑("冻结")。您可以使用以下代码来检查“是否已捆绑”:
import sys if getattr(sys, 'frozen', False) and hasattr(sys, '_MEIPASS'): print('running in a PyInstaller bundle') else: print('running in a normal Python process')当捆绑的应用程序启动时,引导加载程序会设置
sys.frozen属性,并将捆绑文件夹的绝对路径存储在sys._MEIPASS中。对于一个单文件夹捆绑包,这是指向该文件夹的路径。对于一个单文件捆绑包,这是引导加载程序创建的临时文件夹的路径(请参阅单文件程序的工作原理)。在应用程序运行时,它可能需要访问以下位置之一的数据文件:
与其捆绑在一起的文件(请参阅添加数据文件)。
用户放置在应用程序捆绑包中的文件,例如位于同一文件夹中的文件。
用户当前工作目录中的文件。
程序可以访问几个变量来满足这些用途。
因此,这段代码在开发环境下执行会从源码中去加载已经实现的 dcs 接口类,在打包后会从捆绑的包中加载对于的源码。这样写的好处是避免 dcs_dirname 因为包含一个点,导致 pkgutil.iter_importers() 错误地将路径解释为包名的问题。
FrozenImporter是什么 ?
FrozenImporter是 Python 的导入机制中的一个概念,它在冻结(或打包)的应用程序中起着重要作用。在解释FrozenImporter之前,让我们先了解一下 Python 的导入机制。Python 中的导入机制允许你在代码中引用其他模块或脚本,以便重用代码和模块化开发。当你在代码中使用
import语句来导入一个模块时,Python 解释器会按照一定的规则在不同的路径中查找这个模块,然后加载它并使其可用。
FrozenImporter是 Python 导入机制的一个特殊实现,用于处理被“冻结”或“打包”成单个可执行文件的应用程序。当你使用工具如 PyInstaller、cx_Freeze 等将 Python 应用程序打包成单个可执行文件时,这些工具会将应用程序中所需的模块和资源一起打包,以便在不需要原始源代码的情况下运行应用程序。
FrozenImporter的主要功能是从打包的资源中加载模块。它会在运行时根据应用程序的文件结构和打包的内容来定位并加载模块,而无需实际的文件路径。这使得打包的应用程序能够以与原始源代码相同的方式使用导入语句,而无需担心实际文件路径。总之,
FrozenImporter是 Python 导入机制在冻结或打包应用程序中的一种特殊实现,它允许打包的应用程序像正常导入模块一样使用导入语句,从而实现了模块化和资源管理。在前面提到的代码段中,使用FrozenImporter可以避免路径中包含点时pkgutil.iter_importers()的错误解释问题。
# 3. Leader [class]
class Leader(NamedTuple):
"""Immutable object (namedtuple) which represents leader key.
Consists of the following fields:
:param version: modification version of a leader key in a Configuration Store
:param session: either session id or just ttl in seconds
:param member: reference to a `Member` object which represents current leader (see `Cluster.members`)
"""
version: _Version
session: _Session
member: Member
在 Zookeeper 实现类中,Leader 类对象的创建流程:
# 这部分代码位于 zookeeper 的 _cluster_loader 方法中
leader = self.get_node(path + self._LEADER) if self._LEADER in nodes else None
if leader:
member = Member(-1, leader[0], None, {})
member = ([m for m in members if m.name == leader[0]] or [member])[0]
leader = Leader(leader[1].version, leader[1].ephemeralOwner, member)
self._fetch_cluster = member.version == -1
leader 在 Zookeeper 中存储的内容如下:
[zk: localhost:2181(CONNECTED) 3] get /service/test/2/leader
node_172_16_245_4
cZxid = 0x1f0000000f
ctime = Tue Aug 01 22:55:56 EDT 2023
mZxid = 0x1f0000000f
mtime = Tue Aug 01 22:55:56 EDT 2023
pZxid = 0x1f0000000f
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x20009a1dafc0000
dataLength = 17
numChildren = 0
其中 node_172_16_245_4 为该节点存储的数据,下面的是节点状态信息,具体解释如下:
cZxid: 创建事务的 ID(Zxid),表示节点的创建操作的事务 ID。ctime: 创建时间,表示节点的创建时间。mZxid: 最近修改事务的 ID(Zxid),表示节点的最后修改操作的事务 ID。mtime: 最近修改时间,表示节点的最后修改时间。pZxid: 最近修改子节点事务的 ID(Zxid),表示子节点的最后修改操作的事务 ID。cversion: 子节点修改次数,表示子节点的版本号。dataVersion: 数据版本,表示节点数据的版本号。aclVersion: ACL 版本,表示节点的访问控制列表(ACL)的版本号。ephemeralOwner: 临时节点所有者,如果节点是临时节点,则表示拥有该临时节点的会话 ID。dataLength: 数据长度,表示节点存储的数据的长度。numChildren: 子节点数量,表示节点的子节点数量。
而 kazoo 库中 get() 方法返回的内容中包含的 ZnodeStat 信息如下:
creation_transaction_id(*czxid*):导致此znode创建的更改的事务ID。
last_modified_transaction_id(*mzxid*):最后修改此znode的更改的事务ID。
created(*ctime*):此znode创建的时间,从纪元开始的秒数。(ctime以毫秒为单位)
last_modified(*mtime*):此znode最后修改的时间,从纪元开始的秒数。(mtime以毫秒为单位)
version:此znode的数据更改次数。
acl_version(*aversion*):此znode的ACL更改次数。
owner_session_id(*ephemeralOwner*):如果znode是临时节点,则为此znode的所有者的会话ID。如果它不是临时节点,则为None。(如果不是临时节点,ephemeralOwner将为0)
data_length(*dataLength*):此znode的数据字段长度。
children_count(*numChildren*):此znode的子节点数量。
然后我们就可以解释一下这三个参数:
version: 在创建是传入的是leader[1].version获取的正是 zookeeper 中存储的节点状态信息中的cVersion。session: zookeeper 中存储的节点状态信息中的ephemeralOwner参数。member: 为 zookeeper 中存储的/memeber路径下对应的leader节点的信息。
# HA
# 1. post_bootstrap[method]
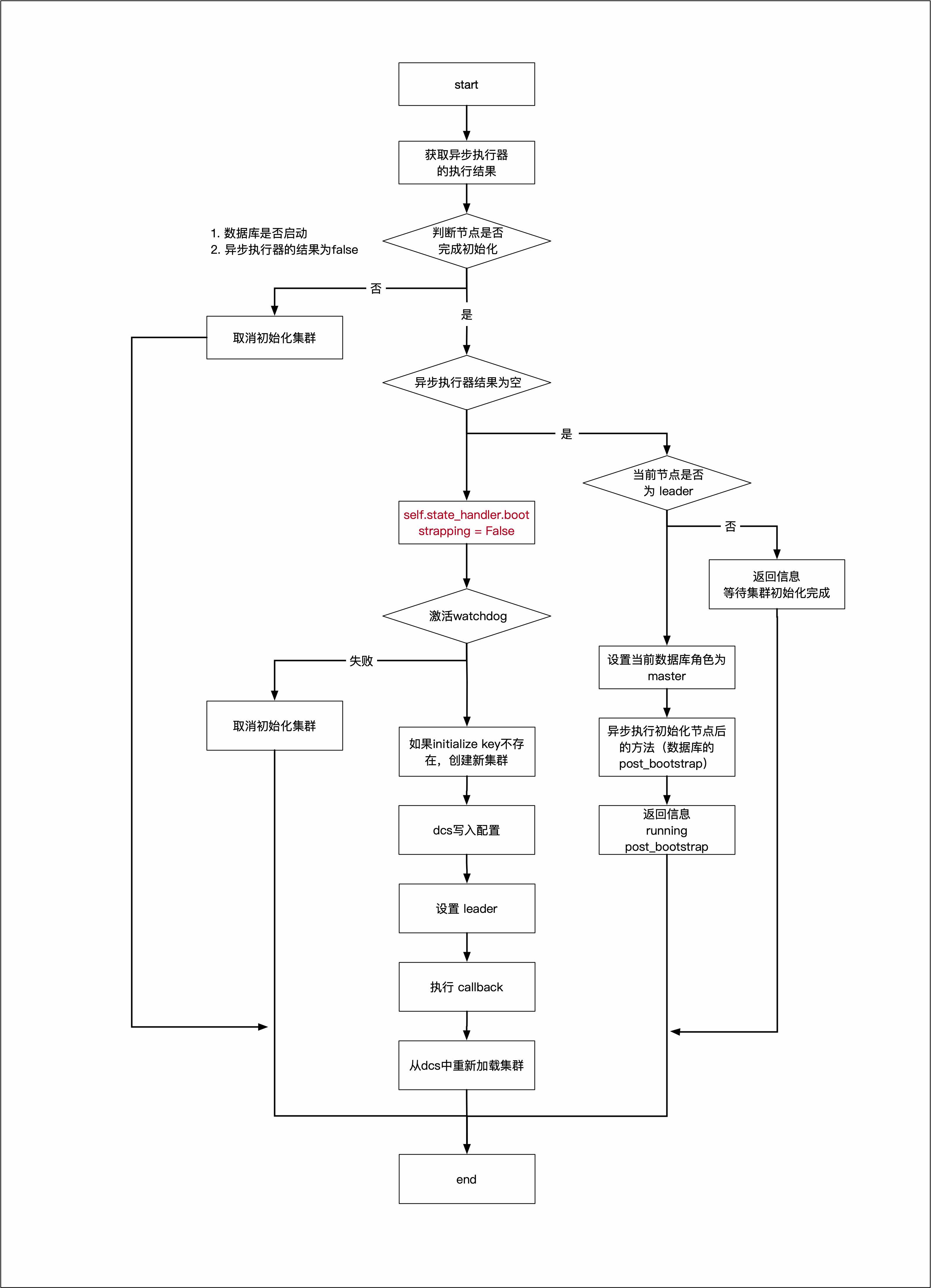
这段代码是一个方法,名为 post_bootstrap,用于在数据库集群引导启动(bootstrap)后进行一系列后续操作。让我逐步解释其主要步骤和逻辑:
- 首先,代码使用
with self._async_response进入一个异步块,从_async_response获取异步操作的结果,存储在变量result中。 - 接下来,代码检查以下情况:
- 如果 PostgreSQL 数据库未运行(
state_handler.is_running()返回False)或者result为False,则调用cancel_initialization方法取消引导初始化,表示引导启动失败。 - 如果
result为None,继续执行后续操作。
- 如果 PostgreSQL 数据库未运行(
- 如果当前节点不是主节点,方法返回字符串
'waiting for end of recovery after bootstrap',表示当前节点正在等待引导启动过程完成。 - 如果当前节点是主节点,代码通过
state_handler.set_role('master')将当前节点设置为主节点。 - 然后,代码使用
_async_executor.try_run_async异步执行名为post_bootstrap的操作,该操作在self.state_handler.bootstrap.post_bootstrap中定义,传递一些参数。操作的结果存储在变量ret中。 - 如果
result不为空,说明引导启动成功,继续执行以下操作:- 将
bootstrapping属性设置为False,表示引导启动完成。 - 激活看门狗(watchdog)以确保故障检测功能正常运行。如果激活失败,记录错误日志并调用
cancel_initialization取消初始化。 - 使用
_rewind.ensure_checkpoint_after_promote方法确保在升级为主节点后进行检查点。 - 初始化分布式一致性服务(DCS):根据情况创建新的集群(如果
cluster.initialize为空),并将系统标识(sysid)传递给 DCS。 - 将动态配置信息序列化并存储到 DCS 配置中。
- 将当前节点设置为主节点。
- 调用
CallbackAction.ON_START来执行节点启动回调操作。 - 从 DCS 中加载集群信息。
- 将
- 最后,方法返回字符串
'initialized a new cluster',表示集群已成功完成初始化。
总之,这个方法在数据库集群引导启动完成后,根据节点的角色和引导启动结果,执行一系列后续操作,包括设置节点角色、激活看门狗、创建检查点、初始化分布式一致性服务等。
# 2. bootstrap [method]
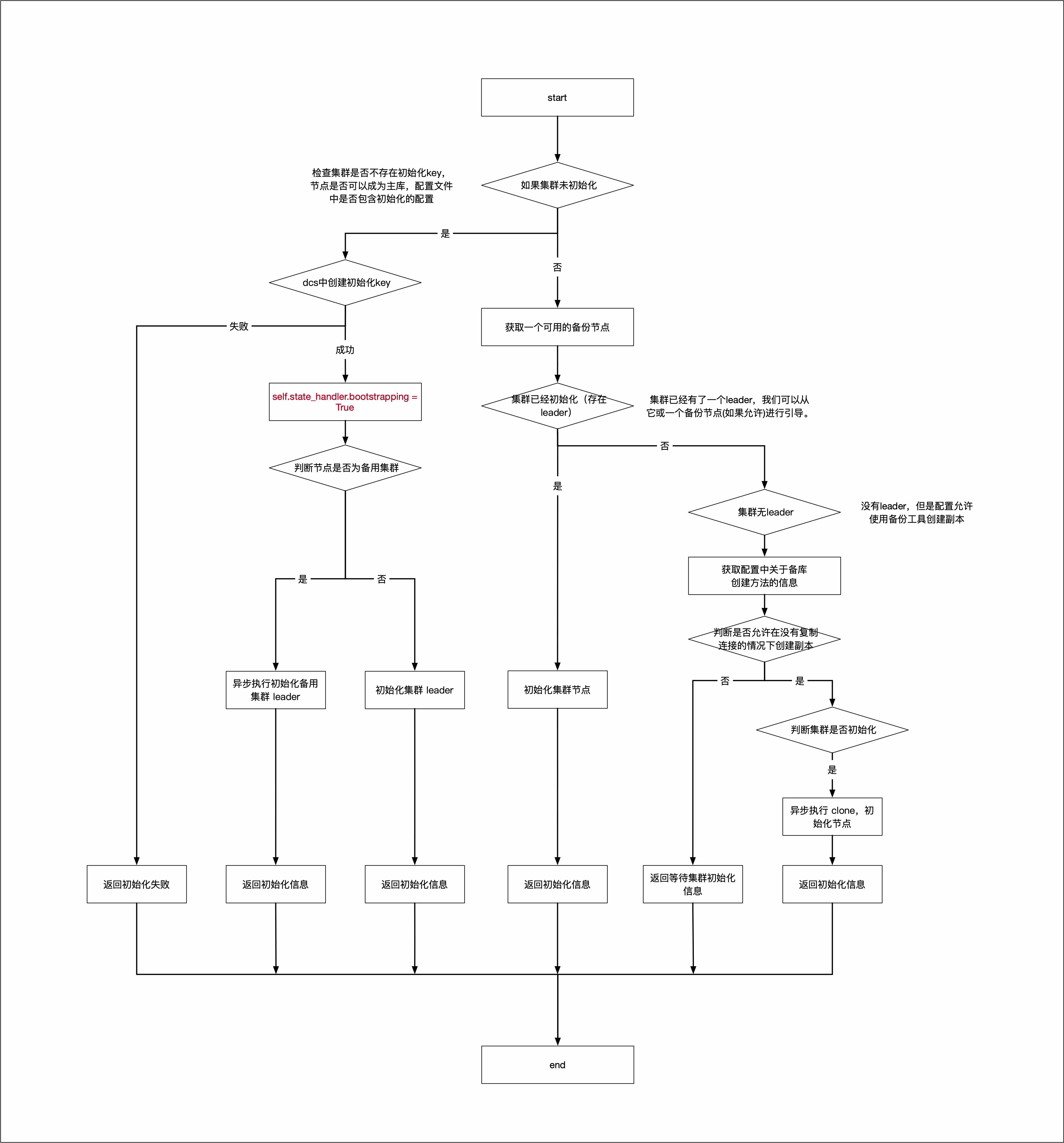
这段代码主要定义了一个名为 bootstrap 的方法,该方法用于在集群引导过程中执行一系列操作。以下是对代码中每个部分的简要解释:
检查是否允许 bootstrap:首先,代码检查是否满足 bootstrap 的条件。要求集群没有被锁定(is_unlocked())、没有初始化密钥(initialize is None)、不禁用故障切换(nofailover 为 False)以及配置文件中存在 "bootstrap" 部分。如果满足这些条件,就可以尝试引导。
尝试引导:在满足引导条件时,代码会尝试执行 bootstrap 操作。它会先尝试获取初始化锁(initialize lock),如果成功获得锁,则进入引导状态。根据集群的不同情况,可能会调用不同的方法来执行引导操作。
检查是否有克隆成员:如果集群已经有了一个领导节点(leader),则可以从领导节点或其中一个从节点(replica)bootstrap。在这种情况下,代码会查找适合 bootstrap 的成员,并调用
clone方法来执行引导操作。检查是否允许无领导节点 bootstrap:如果集群没有领导节点,但配置允许通过备份工具创建从节点,则可以尝试无领导节点 bootstrap。代码会检查是否满足这个条件,并在不允许并发 bootstrap 的情况下执行 bootstrap 操作。
返回 bootstrap 状态:在以上情况都不满足时,代码会返回等待 bootstrap 的状态。根据是否是从节点集群,会返回不同的等待信息。